728x90
중앙대학교 3-2 리눅스 응용 설계 (손용석 교수님) 과목 정리입니다.
Implementation of Spinlock in Linux Kernel


- Big-endian
- next가 low addr
- owner가 high addr
- Little-endian
- owner가 low addr
- next가 high addr
Little Endian and Big Endian
- Little Endian : LSB가 low address에 저장
- Big Endian : MSB가 low address에 저장

- ldrex : global variable (&lock→slock)을 lockval에 대입
- add : lockval에 TICKET_SHIFT 추가한 값을 newval에 대입
- strex : global variable 업데이트
- teq : tmp가 0인지 확인
- bne : tmp가 0이 아니면 1을 return, label 1로 돌아감

- next와 owner가 같으면 spinlock을 획득한 것
- wfe() : spinlock 내부에서 spinning 하는데 드는 power 절약
- smp_mb() : symantic process memory barrier
- dmb : 컴파일러가 코드를 재배치하는 것 방지
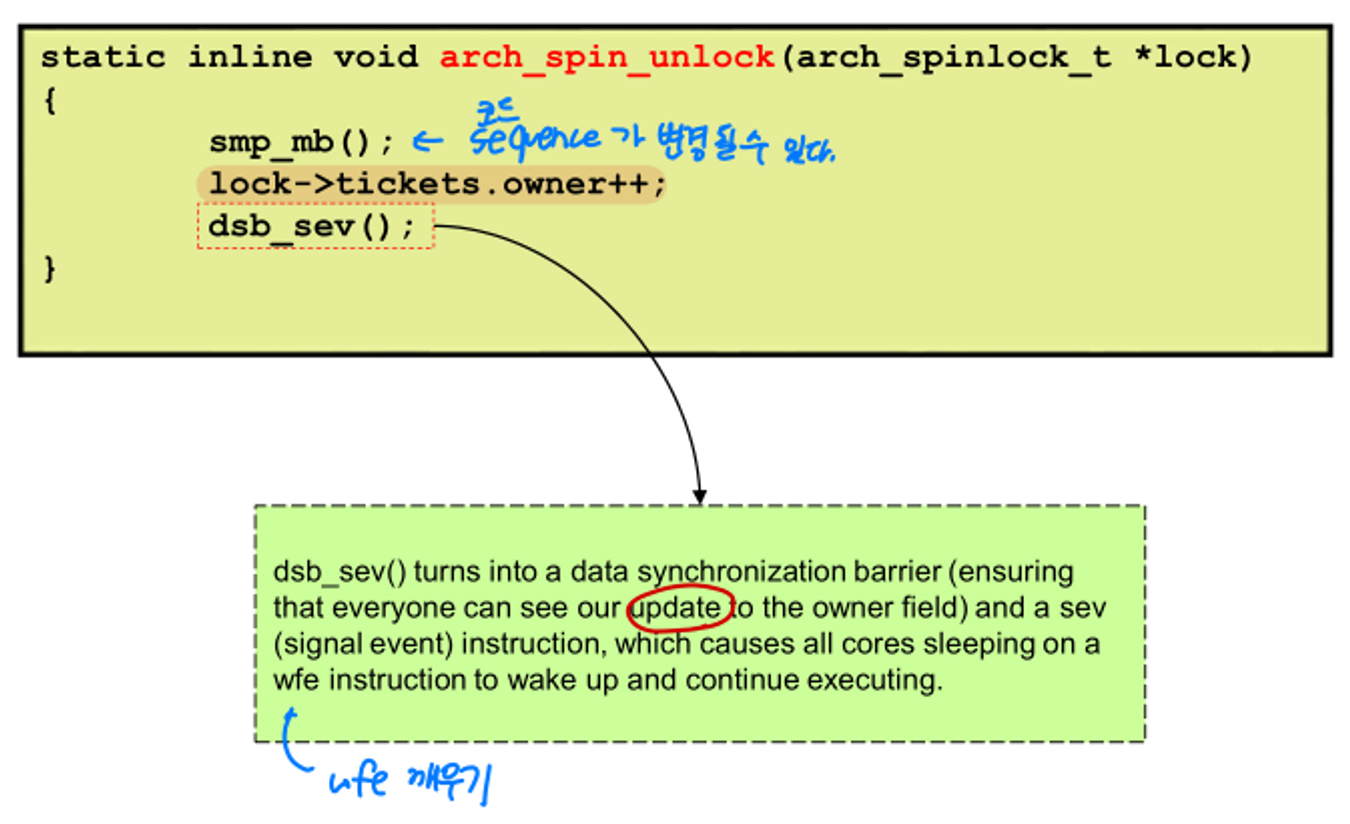
- smp_mb() : 코드 sequence가 변경될 수 있다.
- owner 값 증가
- dsb_sev() : wfe에서 깨우기
Semaphore
- Semaphore는 synchronization mechanism
- multiple threads가 common resource에 접근할 때 사용된다
- multitasking OS 같은 concurrent system에서 critical section problem을 피하기 위해 사용된다.
- sleeping lock
- Semaphore는 integer value를 사용하여 concurrent thread를 관리한다.
- Binary Semaphore : mutex lock. 0, 1개의 값을 갖는다.
- Counting Semaphore : 이용 가능한 resource의 개수를 나타낸다. 이용가능한 resource가 2개라면 2개의 thread가 resource에 접근할 수 있다.
Counting Semaphore
- Counter
- 이용 가능한 resource의 개수를 나타내는 integer variable
- Operations
- Down
- atomically decrease the counter by one (counter > 0)
- acquire a semaphore
- counter가 양수가 될 때까지 sleep (counter == 0)
- Up
- atomically increase the counter by one
- release a semaphore
- Down
Structure for Semaphore
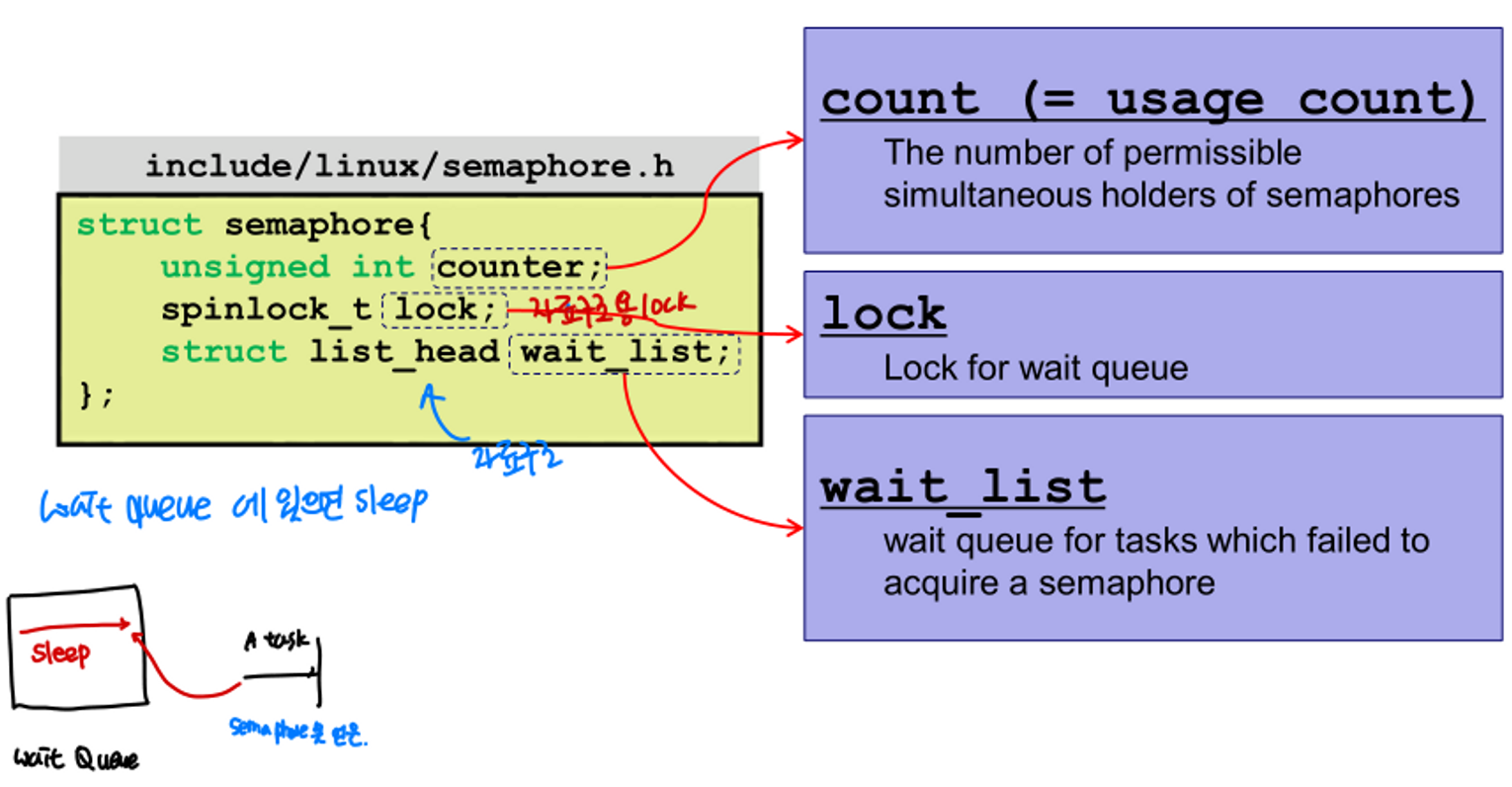
- counter : semaphore를 동시에 사용할 수 있는 thread 개수
- lock : wait queue를 위한 lock
- wait_list : semaphore를 얻는데 실패한 task들이 있는 queue (sleep)

- sema_init : 매개변수 count로 count 초기화
- down : count 감소 (acquire lock)
- up : count 증가 (release lock)
Read / Write Semaphore
- rw_semaphore는 multiple reader, single writer lock mechanism이다.
- 한 명의 writer 또는 여러 명의 reader가 semaphore를 얻을 수 있다.
- semaphore를 얻고 싶어하는 writer는 reader가 semaphore를 갖고 있을 때 blocked state.
- reader 수가 writer 수를 초과할 때 더 높은 성능을 제공한다.
Operations for manipulating rw semaphores
- down_read : read를 위한 rw_semaphore (writer가 semaphore를 갖고 있을 때는 block)
- down_write : writer를 위한 rw_semaphore (reader가 semaphore를 갖고 있을 때는 block)
- up_read : read를 위한 rw_semaphore release
- up_write : write를 위한 rw_semaphore release


- counter를 증가시킬 때 down_write, up_write 사용
- counter를 출력할 때 down_read, up_read 사용
Constraints of Semaphore
- semaphore는 interrupt context에서는 사용될 수 없다.
- interrupt context는 schedulable 하지 않다. (Interrupt handler는 preempt 될 수 없다. interrupt 처리를 뒤로 미루면 task가 계속 밀리게 되기 때문)
- interrupt context에서는 sleeping lock을 쓰면 안 된다.
- semaphore는 spin lock이 이루어지는 동안 사용할 수 없다.
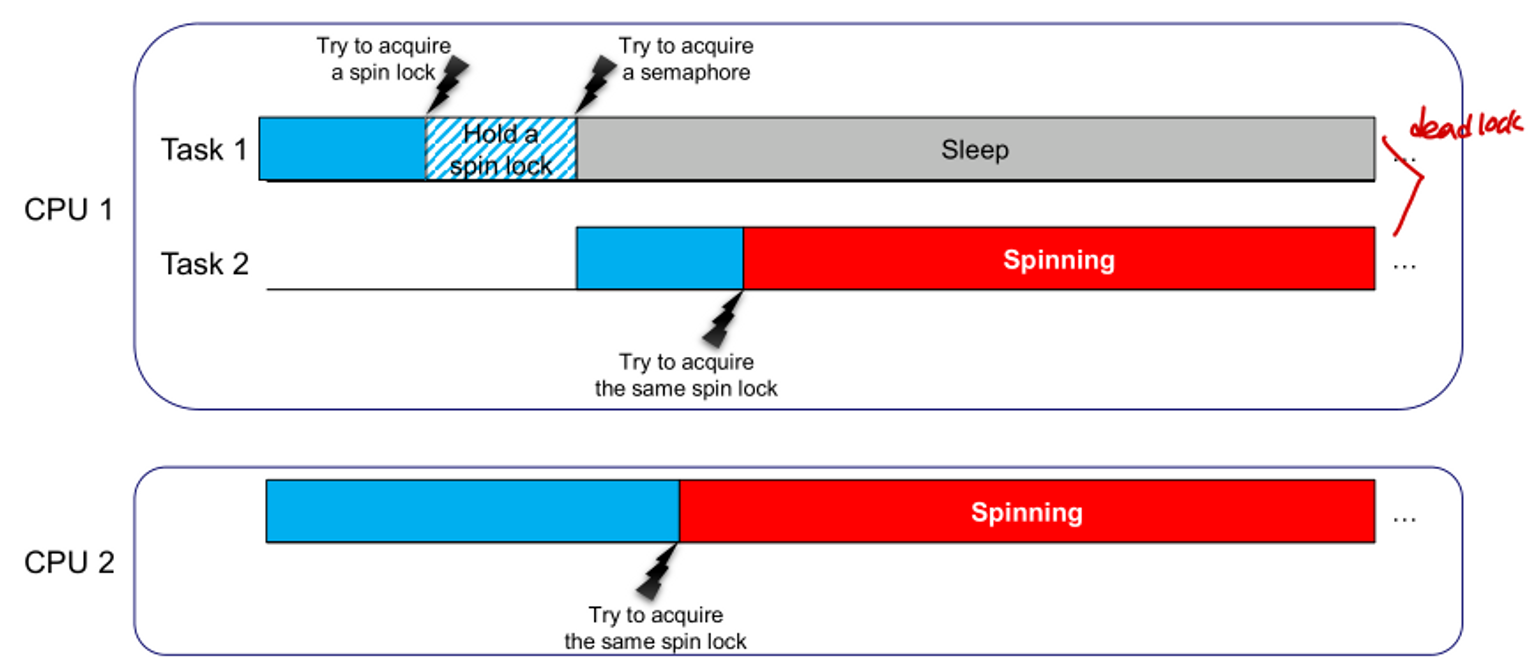
- Task 1은 spinlock을 hold하고 semaphore를 얻는 것을 시도하지만 얻을 수 없으므로 (spin lock 잡고 있어서) sleep
- Task 2는 Task 1이 spinlock 을 hold하고 있기 때문에 spinning
⇒ deadlock 발생
Mutex
- 공유 자원을 보호하기 위한 mechanism
- binary semaphore
- sleeping locks

Structure for Mutex

- count
- 1이면 unlock
- 0이면 locked
- 0보다 작으면 locked, waiter 존재
- wait_lock : wait_list를 위한 lock
- wait_list : mutex를 얻는데 실패한 task들을 위한 queue


Synchronization
- Synchronization은 consistency(일관성)를 보장하지만 concurrency(동시성)는 줄인다.
- Coarse-grained locking
- Fine-grained locking
- Lock-free approach
- Lock-free data structure and operation
- Per-core data structure and operation
Coarse-grained locking
- fewer locks, more objects per lock
- lock 개수는 적지만 lock에 영향 받는 객체가 많다.
- one lock for entire data structure
- 많은 thread들이 하나의 lock을 얻기 위해 경쟁하므로 lock을 얻기 쉽지 않다.

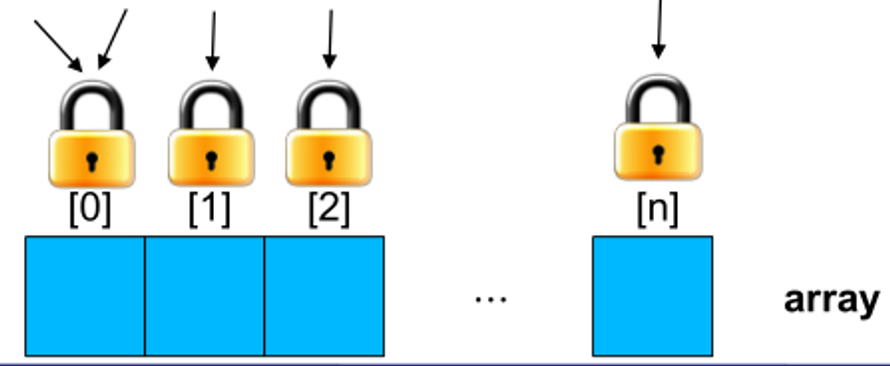
Fine-grained locking
- more locks, fewer objects per lock
- lock 개수가 많고, lock에 영향 받는 객체가 적다.
- one lock per data element (array index)
- concurrency를 증가시킬 수 있다.
Lock-free data structure and operation
- lock이 없고, 대신에 atomic instruction을 사용한다.

Per-core data structure and operation
- atomic instruction을 사용하지 않고, per-core variable과 data structure를 생성한다.
- per-CPU variable과 data structure를 생성할 때, system의 각 processor는 각각 variable과 data structure의 copy를 갖게 된다.
- 그러나 마지막에는 synchronization이 필요하게 되는데, 이때는 timestamp를 사용한다. (누가 가장 마지막에 값을 변경했는지 확인)

Atomic Operation vs Locking Mechanism
- Atomic operation advantage
- lock에 비해 상대적으로 빠르고 deadlock에 시달리지 않는다.
- Atomic Operation disadvantage
- 제한된 operation만 실행 가능하고, 더 복잡한 operation을 효율적으로 통합하기에는 충분하지 않다.

728x90
'School Lecture Study > Linux System Application Design' 카테고리의 다른 글
| 7-2. Task Scheduling in Linux (2) (0) | 2022.12.20 |
|---|---|
| 7-1. Task Scheduling in Linux (1) (0) | 2022.12.20 |
| 6-3. Synchronization (3) (0) | 2022.12.20 |
| 6-2. Synchronization (2) (1) | 2022.12.20 |
| 6-1. Synchronization (1) (0) | 2022.12.20 |